7월 2주차 프로보노 프로젝트 회의에서 머신러닝 모델(알고리즘)을 드디어 확정했다.
STT의 결과물인 Text 데이터의 맥락을 파악한 후 보이스피싱인지 아닌지 판별해야하기 때문에, 순차적인 데이터 처리가 필요하다고 생각했고, RNN 모델이 적합하다고 판단하여 RNN으로 확정하게 되었다.
이 글은 RNN와 그 발전 모델인 LSTM 에 대한 공부가 필요하다고 생각해 작성한 글이며 개인적인 공부 백업용이다.
전통적인 신경망은 앞뒤 맥락을 파악하지 못한다는 한계점이 있다. 예를 들어, 영화의 매 순간 일어나는 사건을 분류하고 싶다고 해보자. 전통적인 neural network는 이전에 일어난 사건을 바탕으로 나중에 일어나는 사건을 생각하지 못한다.
1. RNN
RNN (Recurrent neural network) 는 이 문제를 해결하고자 하는 모델이다. RNN 은 스스로를 반복하는 순환 구조로 이전 단계에서 얻은 정보가 지속되도록 한다.

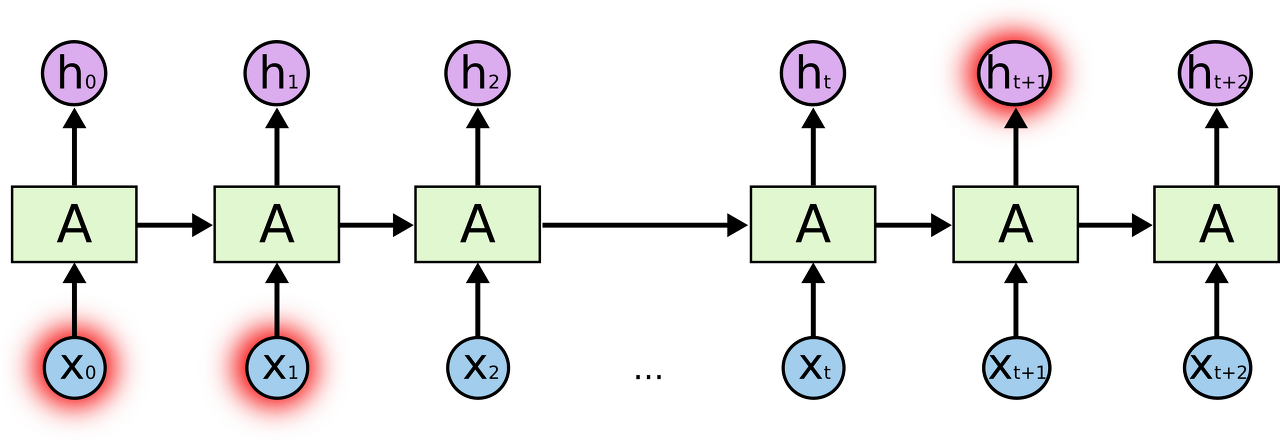
위 그림에서 A는 RNN의 한 덩어리이다. A는 input xtxt를 받아서 htht를 내보낸다. A를 둘러싼 반복은 다음 단계에서의 network가 이전 단계의 정보를 받는다는 것을 보여준다.
위의 그림은 하나의 구조이고, RNN은 이것이 여러개 반복되는 구조를 가지는데 다음과 같다.

RNN 처럼 체인으로 이어지는 성질은 음성인식, 언어 모델링, 번역, 이미지 주석 생성 등 다양한 분야에서 사용되고 있다. 우리 프로젝트의 주제인 Text classification 도 이와 관련이 있다.
RNN의 수학적인 맥락은 유튜브 (https://www.youtube.com/watch?v=PahF2hZM6cs&t=405s) 를 보면 잘 이해된다. 물런 아직 100% 이해한 건 아니다..
2. RNN 문제?
LSTM은 RNN의 특별한 종류로, 위에서 이야기했던 영화를 frame 별로 이해하는 것과 같은 문제들을 단순 RNN보다 쉽게 해결할 수 있게된다.
현재 시점에서 뭔가를 알아내기 위해 멀지 않은 최근의 정보만 필요로 할 때도 있다. 예를들어 이전 단어들을 토대로 다음에 올 단어를 예측하는 모델을 생각해보면, "the clouds are in the sky"에서의 마지막 단어를 맞추고 싶다면, 저 문장 말고는 더 볼 필요도 없다. 마지막 단어는 sky일 것이 분명하다. 이 경우처럼 필요한 정보를 얻기 위한 시간 격차가 크지 않다면, RNN도 지난 정보를 바탕으로 학습할 수 있다.

반대로 더 많은 문맥을 필요로 하는 경우도 있다. "I grew up in France... I speak fluent French"라는 문단의 마지막 단어를 맞추고 싶다고 생각해보자. 최근 몇몇 단어를 봤을 때 아마도 언어에 대한 단어가 와야 될 것이라 생각할 수는 있지만, 어떤 나라 언어인지 알기 위해서는 프랑스에 대한 문맥을 훨씬 뒤에서 찾아봐야 한다. 이렇게 되면 필요한 정보를 얻기 위한 시간 격차는 굉장히 커지게 된다. 안타깝게도 이 격차가 늘어날 수록 RNN은 학습하는 정보를 계속 이어나가기 힘들어한다.
RNN이 긴 의존 기간의 문제를 어려워하는 꽤나 핵심적인 이유들을 찾아낸 논문이 존재한다.
3. LSTM Networks
LSTM은 RNN의 특별한 한 종류로, 긴 의존 기간을 필요로 하는 학습을 수행할 능력을 갖고 있다.
모든 RNN은 neural network 모듈을 반복시키는 체인과 같은 형태를 하고 있다. 기본적인 RNN에서 이렇게 반복되는 모듈은 굉장히 단순한 구조를 가지고 있다. 예를 들어 tanh layer 한 층을 들 수 있다.
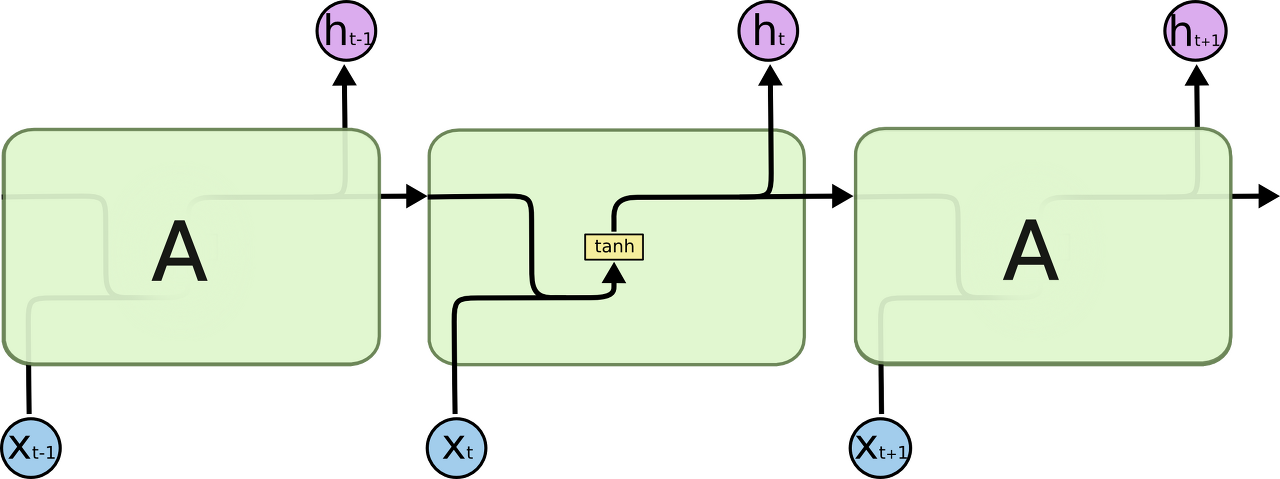
RNN의 반복 모듈이 단 하나의 layer를 갖고 있는 표준적인 모습이다.
LSTM도 똑같이 체인과 같은 구조를 가지고 있지만, 각 반복 모듈은 다른 구조를 갖고 있다. 단순한 neural network layer 한 층 대신에, 4개의 layer가 특별한 방식으로 서로 정보를 주고 받도록 되어 있다.
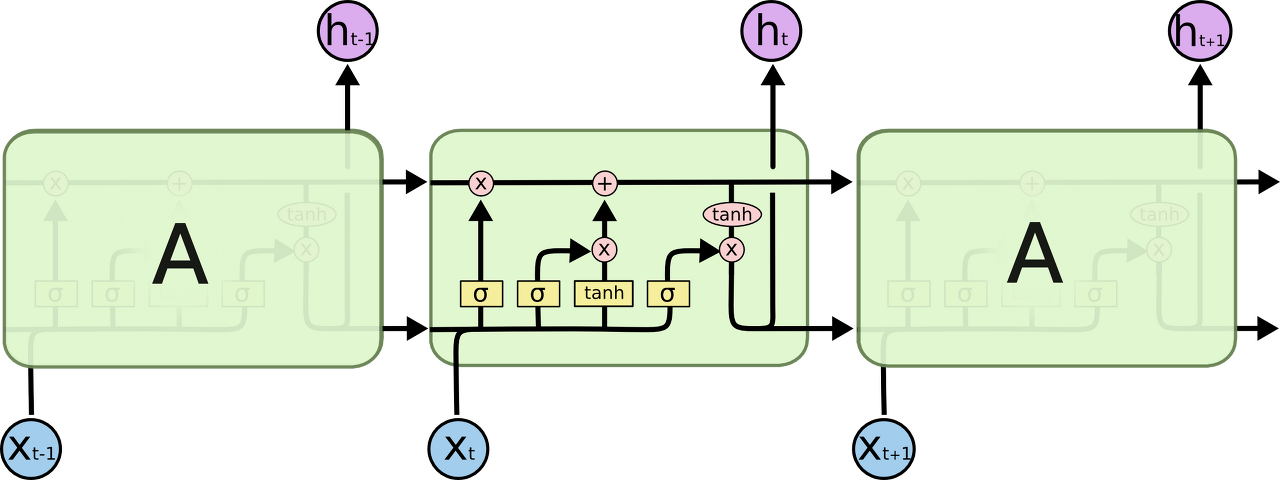
LSTM의 반복 모듈에는 4개의 상호작용하는 layer가 들어있다.

위 그림에서 각 선(line)은 한 노드의 output을 다른 노드의 input으로 vector 전체를 보내는 흐름을 나타낸다. 분홍색 동그라미는 vector 합과 같은 pointwise operation을 나타낸다. 노란색 박스는 학습된 neural network layer다. 합쳐지는 선은 concatenation을 의미하고, 갈라지는 선은 정보를 복사해서 다른 쪽으로 보내는 fork를 의미한다.
유튜브는 (https://www.youtube.com/watch?v=bX6GLbpw-A4) 이 영상을 보면 이해가 쉽다.
참고 & 출처
https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
Long Short-Term Memory (LSTM) 이해하기
이 글은 Christopher Olah가 2015년 8월에 쓴 글을 우리 말로 번역한 것이다. Recurrent neural network의 개념을 쉽게 설명했고, 그 중 획기적인 모델인 LSTM을 이론적으로 이해할 수 있도록 좋은 그림과 함께
dgkim5360.tistory.com
난 왜이렇게 멍청할까.. 왜이렇게 이해가 안되지 기계학습 너무 어려워
'프로젝트 > 2021 한이음(probono)' 카테고리의 다른 글
| [프로보노프로젝트/딥러닝] 텍스트 데이터 양 늘리기 (Text Data Augmentation) (4) | 2021.08.09 |
|---|---|
| [프로보노프로젝트/오류해결] AttributeError: 'float' object has no attribute 'lower' (0) | 2021.07.31 |
| [프로보노프로젝트/딥러닝] 자연어 처리(NLP) 토큰화(Tokenization) (0) | 2021.07.28 |
| [프로보노프로젝트/딥러닝] 딥러닝 기초 (0) | 2021.07.16 |
| [프로보노 프로젝트] ICT 수행계획서 작성 (1) | 2021.04.17 |