4월부터 시작한 프로보노 프로젝트도 어느새 중간보고서를 제출하고 승인까지 받게 되었다. 프로젝트 초기에는 머신러닝 엔진을 개발하는 역할을 맡았지만, 후에 데이터 전처리를 하는 팀원을 도와 데이터 전처리 개발에 집중하게 되었다. 현재 데이터 전처리 개발은 어느정도 완성된 상태이기에 백업용으로 이 글을 작성한다.
*개발내용 뿐 아니라 팀원들과 했던 커뮤니케이션과 문제 해결 과정, 회의내용도 어느정도 백업하려한다.
우리팀의 진행 방향성과 느낀점
멘토님께서는 우리가 개발을 하면서 이것을 해야하는 본질적인 이유에 대해 잊지 않는 것을 강조하셨다. 그래서 팀장님도 매번 우리팀이 전처리를 해야하는 이유에 대해 상기시켜 주셨고, 더 나아가 우리의 주제가 무엇인지 왜 머신러닝을 사용해야하는지 등 원초적인 목적에 대해 자꾸 물어봐주셨다.
덕분에 개발 흐름을 이해하는데 도움이 많이 되었고, 개발하면서 길을 잃지 않고 목표로 나아갈 수 있었다.
개발 기간은 각자 머신러닝 공부와 논문들을 찾아보고 본격적으로 개발을 시작한 건 7월 둘째주부터이니 전처리에만 1달이 걸린 셈이다.
원래는 역할분담을 통해 데이터 전처리 개발에 한 명을 배정했지만 한 사람이 개발을 다 하기에는 너무 무리가 있었기 때문에 나도 같이 개발을 맡게 되었다. (막판엔 다같이 하긴 했다..)
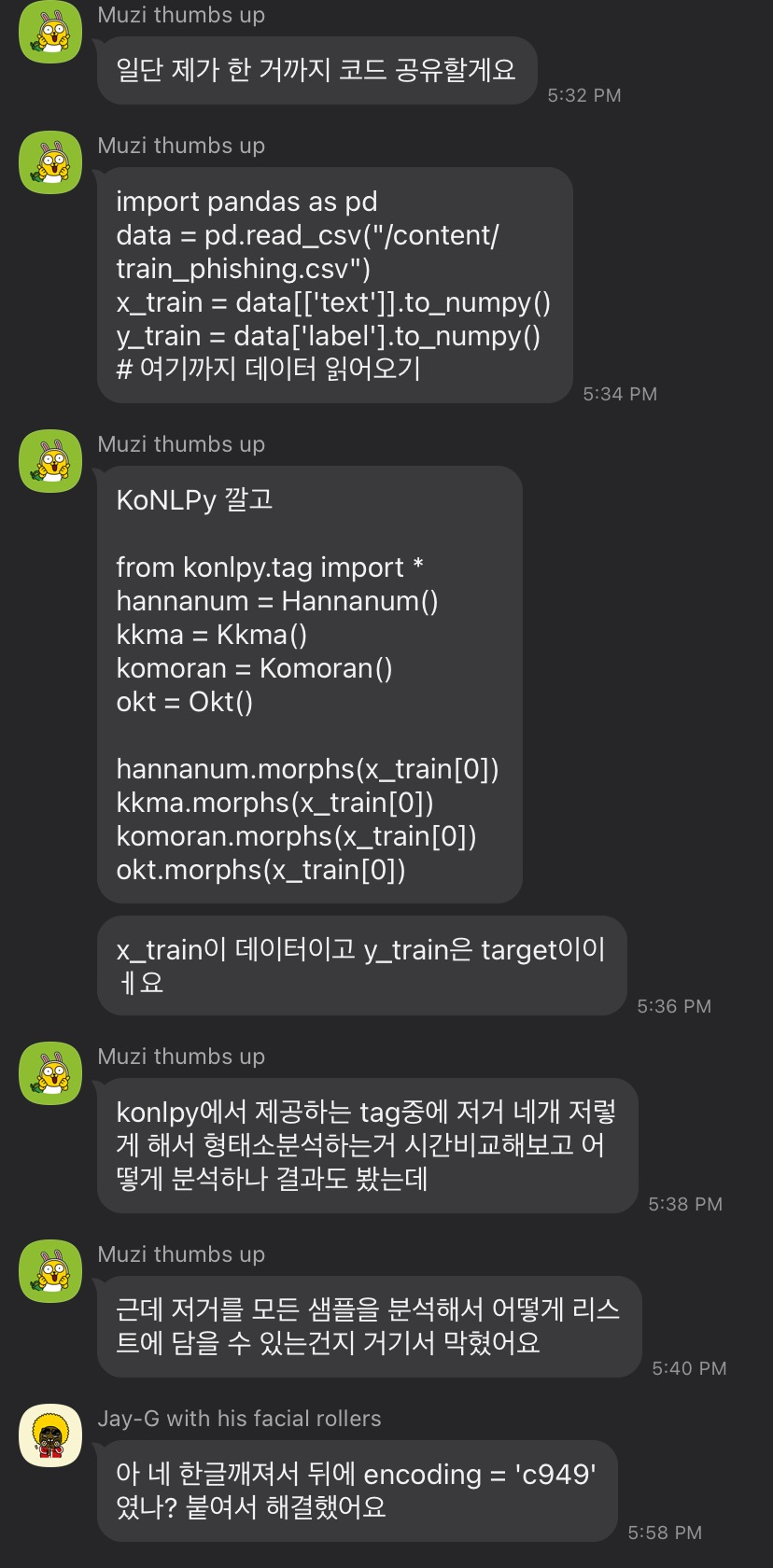
우리팀은 Git명령어에 익숙하지않기도 했고, 아직 커밋을 할 단계는 아니라고 생각했기 때문에 Git을 사용하기 보다는 구글 Colab에서 이메일로 코드를 공유하여 같이 개발하는 식으로 진행하였다. 회의할 때 같이 코드를 짜고 그 다음 회의 전까지 오류를 잡는식으로 말이다. 또한, 새로운 이슈나 오류 해결 내용이 생기면 단체채팅방에 공유하였다.
초기에는 전처리 목표를 정해놓고 각자 코드를 짜오는 식으로 진행했었는데 그렇게 하다보니 다 합쳐서 1의 효율밖에 나지 않는다는 것을 알게되었다. 당연한 것이 자신의 코드를 공유하지 않고 마음대로 짠 코드는 재활용할 수 없으며(변수 작성법, 연결성 등) 서로가 알아보기도 어려웠다. 따라서 위와같은 방법을 사용하였더니 팀원이 짠 코드도 내가 이해할 수 있고 그 다음 코드도 이어서 짤 수 있기에 도합 3 그 이상의 효율을 낼 수 있었다. (짱!)



느낀점.. 힘들다..(다음에다시생각나면쓸래요..)
데이터 전처리를 해야 하는 이유

우리팀이 데이터 전처리를 해야하는 이유는 다음과 같다.
우리팀이 하고자 하는건 텍스트 분류이고 그러려면 모델에 텍스트 데이터를 넣어야 한다. 컴퓨터는 문자가 아닌 0과 1로 이루어진 숫자만 인식할 수 있으므로 텍스트를 숫자로 변환하는 과정이 필요하다. 또한, 전처리를 하지 않으면 데이터의 크기가 커져 제대로 기계를 학습시킬 수 없다.
데이터 전처리 코드 설계
보이스피싱 음성을 text로 변환한 데이터가 우리팀의 데이터 셋이므로 자연어 처리(NLP)가 주된 관심사였다. 후에 깃허브에 완성된 코드를 커밋하면 링크를 올리겠다.
Github -
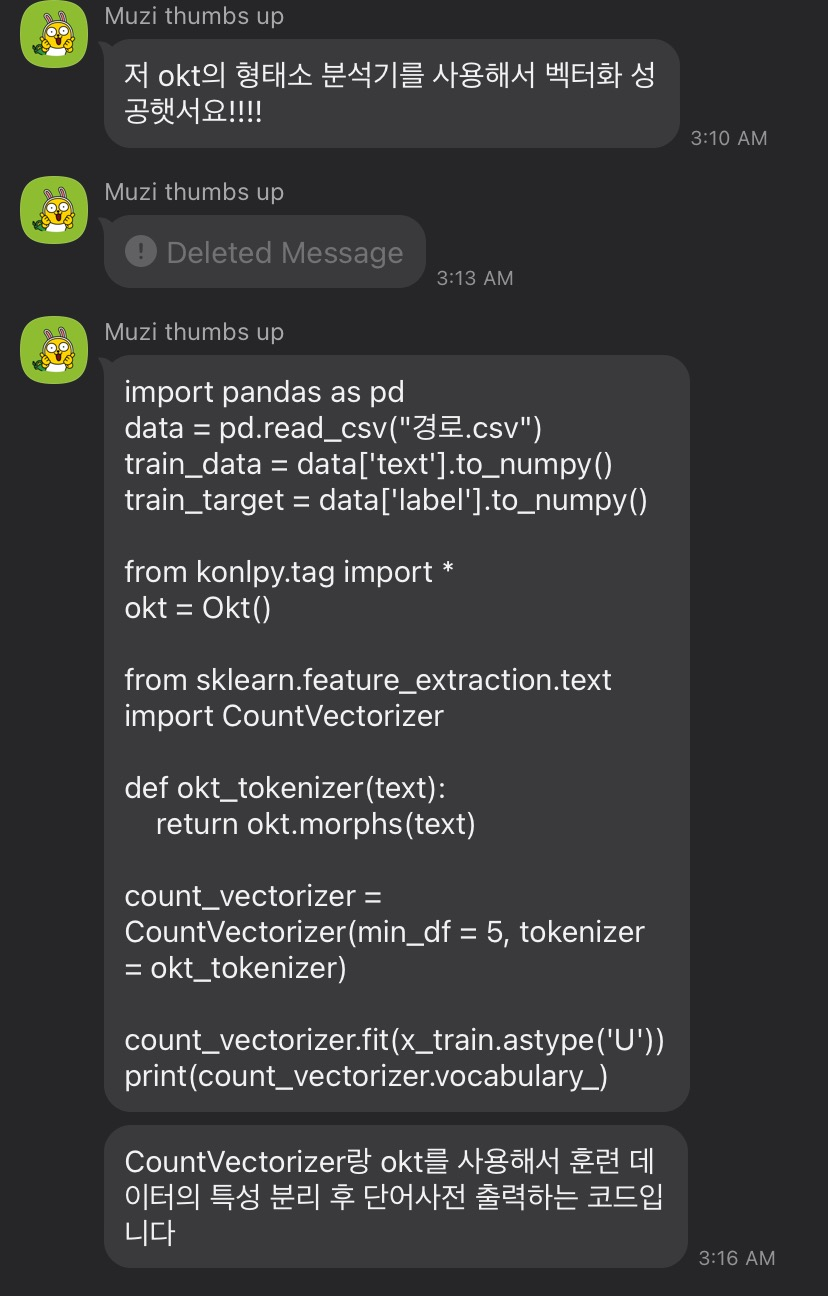
한국어 자연어처리는 영어보다 더 어렵기 때문에 우선 형태소 단위로 문장 분리, 문장에서 명사 추출, 품사 태킹등 한국어 자연어 처리 패키지 중 okt를 사용하여 명령어를 사용해보았다.
from konlpy.tag import Okt
okt = Okt()
sentence = '일단 잘 알겠구요. 저희들이 KB 금융 예로 KB 저축은행인데요. 지금 5월달에 저희들이 자급적으로 나온 대출상품이 있어요. 네 그리고 님 직접 8프로 대로 진행하는 부분이고 상환기간이 5년까지고요. 중도 상환가능하고 수수료 발생에 지금 원리금균등분할 상환 혹은 만기시 상환적으로 이자만 갚으시면 되는 부분이에요. 네 그리고 자급적으로 5천만원까지인데 5천만원부터 받으실거예요? 일단 잘 알겠구요. 맞으시죠? 예. 고객님 혹시 지금 그 사용하고 계신 휴대폰은 본인 이름으로 돼있는거 맞으세요? 예 통신사는 SKT예요 LG예요. 예 삼성 스마트폰 맞으세요? 혹시 카톡은 사용하고 계세요? 그러면은요 카톡 추가를 해서 저희 상호하고 제 이름 넣어드릴게요. 어.. 고객님 저한테 전화를 주셔서 통화중에 제가 전화를 못받으면 카톡으로 연락을 할 수도 있어서 그러는 거 아니에요. 예?'
print("형태소 단위로 문장 분리")
print("-----------------------")
print(okt.morphs(sentence))
print(" ")
print("문장에서 명사 추출")
print("-------------------")
print(okt.nouns(sentence))
print(" ")
print("품사 태킹(PoS)")
print("-------------")
print(okt.pos(sentence))머신러닝 개발을 파이썬으로 하는건 처음이여서 구글링을 통해 공부했고, 도서관에서 딥러닝 개발 관련 책을 읽으며 예제로 공부하는 시간이 필요했다.
어느정도 파이썬 기본 예제들을 학습한 뒤 우리팀의 데이터 전처리 방향성에 대해 논의했는데 토큰화-> 불용어 처리 -> 어휘사전 만들기 -> transform 이다.
토큰화는 데이터 셋을 일정 기준으로 분리하여 토큰화 시키는 작업이다.
불용어 처리는 불용어 리스트를 만들어서 데이터 셋에 있는 필요없는 단어들을 빼버리는 작업이고
어휘사전은 ~~
transform은 ~~
이다.
데이터 전처리 프로그래밍
사용한 패키지 : konlopy,numpy, pandas, tensorflow(keras),nltk
1. 토큰화
import pandas as pd data = pd.read_csv('textvp.txt', sep='\t')
data[:50]
#xy=np.loadtxt('textvp.txt',delimiter='.',dtype=np.float32)
#x_data=xy[:,0:-1]import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
example = '일단 잘 알겠구요. 저희들이 KB 금융 예로 KB 저축은행인데요. 지금 5월달에 저희들이 자급적으로 나온 대출상품이 있어요. 네 그리고 님 직접 8프로 대로 진행하는 부분이고 상환기간이 5년까지고요. 중도 상환가능하고 수수료 발생에 지금 원리금균등분할 상환 혹은 만기시 상환적으로 이자만 갚으시면 되는 부분이에요. 네 그리고 자급적으로 5천만원까지인데 5천만원부터 받으실거예요? 일단 잘 알겠구요. 맞으시죠? 예. 고객님 혹시 지금 그 사용하고 계신 휴대폰은 본인 이름으로 돼있는거 맞으세요? 예 통신사는 SKT예요 LG예요. 예 삼성 스마트폰 맞으세요? 혹시 카톡은 사용하고 계세요? 그러면은요 카톡 추가를 해서 저희 상호하고 제 이름 넣어드릴게요. 어.. 고객님 저한테 전화를 주셔서 통화중에 제가 전화를 못받으면 카톡으로 연락을 할 수도 있어서 그러는 거 아니에요. 예?'
stop_words = pd.read_csv('stop_words.txt',names = ['words'], encoding='utf-16')
stop_words_new = pd.read_csv('stop_words_new.txt',names = ['words'], encoding='utf-16')
word_tokens = okt.morphs(example)
stop_data = np.array(stop_words_new['words']).tolist()
result = []
for w in word_tokens:
if w not in stop_data:
result.append(w)
print(word_tokens,'\n')
print(result)밑에서 불용어 처리가 잘 되지 않자 stop_words_new라는 파일에 기존 많이 쓰이는 불용어 + 우리의 샘플에서 처리되었으면 하는 불용어를 추가한 파일을 새롭게 만들었다. stop_words와 stop_words_new 의 불용어 차이를 보았을 때 샘플 1번의 불용어 처리로는 다음과 같다. 약 30개정도 더 향상된 성능을 보여준다.


import pandas as pd
text_data = pd.read_csv('textvp.txt',names=['data','label'] , sep='|')
text_train = text_data['data'].to_numpy()
text_target=text_data['label'].to_numpy()
print(text_train[:10])
print(text_train.shape)
print(text_data.shape)
#t = Tokenizer()
#t.fit_on_texts(s)
#print(t.word_index)
#for data in train_data:
# word = okt.nouns(train_data)
#for data in train_data:
# train_token=okt.morphs(train_data)
result = []
for text in text_train:
tokenSet=okt.morphs(text)
result.append(tokenSet)stop_words_new
2. 불용어 처리
tokenize = []
for text in text_train:
tokenSet = okt.morphs(text)
tokenize.append(tokenSet)result = []
body = []
for tokenSet in tokenize:
for token in tokenSet:
if token not in stop_data:
result.append(token)
body.append(result)
result=[]
#result엔 뭐가 들어있는거지
print("토큰화 한 샘플(tokenize) = ",tokenize[149]) #토큰화 한 샘플
print("불용어 처리 된 샘플(body) = ",body[149]) #불용어 처리 된 샘플
print(len(tokenize[149]))
print(len(body[149]))
#문제: 숫자랑 문자로 표현된 숫자 불용어 처리 어떻게 할 건지우리가 가장 시간이 많이 걸렸던 부분이 불용어 처리 부분이다. 데이터셋에서 샘플을 추출하여 토큰화 시키고 새로운 리스트에 담아서 그 중 불용어에 포함되지 않는 부분만 새로운 리스트에 추가하는 코드를 짰는데 불용어 처리하는 부분이 잘 처리되지 않았기 때문이다.
3. 어휘사전 만들기
from tensorflow.keras.preprocessing.text import Tokenizer
t = Tokenizer()
t.fit_on_texts(body)
print(t.word_index)
sequence_data = t.texts_to_sequences(body) #transform
print(sequence_data[0])np.set_printoptions(threshold=np.inf)
#print(t.word_index)
#print(len(t.word_index))
hj=list(t.word_index)
#print(hj)
hjdata=np.array(hj)
type(hjdata)
hjdata.reshape(-1,10)
#print(t.word_counts)
4. transform (아직)
'프로젝트 > 2021 한이음(probono)' 카테고리의 다른 글
| [프로보노프로젝트/딥러닝] 패딩 (Padding) (2) | 2021.08.25 |
|---|---|
| [프로보노프로젝트/딥러닝] KOR_EDA 정리 (EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks) (0) | 2021.08.11 |
| [프로보노프로젝트/딥러닝] 텍스트 데이터 양 늘리기 (Text Data Augmentation) (4) | 2021.08.09 |
| [프로보노프로젝트/오류해결] AttributeError: 'float' object has no attribute 'lower' (0) | 2021.07.31 |
| [프로보노프로젝트/딥러닝] 자연어 처리(NLP) 토큰화(Tokenization) (0) | 2021.07.28 |