2021.08.09 - [프로젝트/한이음(probono)] - 텍스트 데이터 양 늘리기 (Text Data Augmentation)
위 글에서 언급했듯 우리팀은 데이터셋의 종류가 적어 텍스트 데이터 셋의 개수를 증가시키는 코드를 개발해야 한다.
관련 연구로는 2019년 EMNLP에서 발표된
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks가 있다.
논문을 읽어보았지만, 잘 이해가 되지 않는 부분은 https://catsirup.github.io/ai/2020/04/21/nlp_data_argumentation.html 를 참고하였다.
학습 데이터가 부족한 상황에서 데이터를 변형시켜 그 양을 늘리는 방법을 데이터 증강 (DATA Augmentation)이라고 한다. 보통 CNN과 같은 이미지 처리에서는 활발하게 사용하고 있지만, 자연어 처리(NLP) 분야에서는 단어 하나만 바뀌어도 문장의 의미가 전혀 달라지기 때문에 DATA Augmentation 을 활용하기가 쉽지 않았다.
구글링하다가 해당 논문에 대한 좋은 자료가 있길래 정리하여 남겨놓는다.
논문 요약 (Abstract & Introduction)
EDA : Easy Data Augmentation, 쉽게 데이터를 증강하는 프로그램을 개발한 논문, 특히 이 논문에서는 텍스트 데이터의 증강을 다뤘다.
데이터를 증강하는 방법에는 총 네 가지가 있는데
- SR: Synonym Replacement, 특정 단어를 유의어로 교체
- RI: Random Insertion, 임의의 단어를 삽입
- RS: Random Swap, 문장 내 임의의 두 단어의 위치를 바꿈
- RD: Random Deletion: 임의의 단어를 삭제
이다.
EDA가 합성망(CNN)과 순환신경망(RNN)+LSTM 에서 성능을 향상시킨다는 것을 보여주는데, 특히나 데이터가 적은 경우에 더 강력하다고 한다. 데이터의 양이 많아지면 노이즈를 생성시켜도 어느정도 데이터 이상이면 영향을 줄 수 없으니 당연한 결과라고 생각한다.
보통 CNN과 같은 컴퓨터 비전이나 음성에서 훈련 데이터의 양이 적을 경우, DATA Augmentation을 하면 이미지를 뒤집거나, 각도를 조금씩 회전하여 데이터를 변형시킨다. 고양이 이미지를 뒤집거나 각도를 회전시키거나 노이즈를 준다고 해서 고양이가 아니게 되는 것은 아니기 때문에 이런 경우에는 어규멘테이션이 효과적이다.
그러나 자연어 처리(NLP)에서는 이런 방식을 사용하기가 매우 어렵다. 단어의 뜻만 바뀌어도 문장의 의미 자체가 바뀌어버릴 수가 있기 때문이다. 이로인해 NLP의 어규멘테이션 기법은 다른 분야에 비해 발전이 더뎠다.
이전에 제안되었던 NLP 데이터 증강 기법에는
- 문장을 프랑스어로 번역하고 다시 영어로 번역해서 새로운 데이터를 얻어내는 방식.
- 데이터에 노이즈를 가볍게 주는 방식(data noising as smoothing)
- 유의어로 교체해주는 예측 언어 모델
이렇게 세 가지가 있다. 이런 기술이 유효하긴 한데, 성능 대비 구현 비용이 높아 잘 사용되지 않는다고 한다. 그래서 이 논문은 EDA라고 부르는 보편적인 데이터 증강 기법을 제안한다.
EDA
논문에서 소개된 EDA의 기법에는 다음과 같은 것이 있다.
- 동의어 교체(Synonym Replacement, SR): 문장에서 랜덤으로 stop words가 아닌 n 개의 단어들을 선택해 임의로 선택한 동의어들 중 하나로 바꾸는 기법.
- 무작위 삽입(Random Insertion, RI): 문장 내에서 stop word를 제외한 나머지 단어들 중에서, 랜덤으로 선택한 단어의 동의어를 임의로 정한다. 그리고 동의어를 문장 내 임의의 자리에 넣는걸 n번 반복한다.
- 무작위 교체(Random Swap, RS): 무작위로 문장 내에서 두 단어를 선택하고 위치를 바꾼다. 이것도 n번 반복
- 무작위 삭제(Random Deletion, RD): 확률 p를 통해 문장 내에 있는 각 단어들을 랜덤하게 삭제한다.
EDA Results
EDA를 CNN과 RNN+LSTM에서 테스트했으며, 다섯 개의 랜덤 시들 부터 나온 결과의 평균을 냈다.

다양한 학습셋 크기에 대해 5개의 데이터셋에 걸쳐 EDA를 포함하거나 포함하지 않고 CNN과 RNN모델을 모두 실행했다고 한다. 성능에 대한 평균은 표 2에 작성했다. 평균적으로 전체 데이터셋을 사용할 경우 0.8%의 성능 향상이 있었다.
How much augmentation?
그럼 한 문장 당 얼마나 증강하는게 가장 적합할까? 아래 그림은 문장 당 {1,2,4,8,16,32} 개만큼 증강했을 때에 대한 결과를 보여준다. 작은 훈련 셋에서는 과적합이 발생할 가능성이 더 높기 때문에 문장을 많이 생성할 수록 더 큰 성능 향상을 얻을 수 있다고 한다.
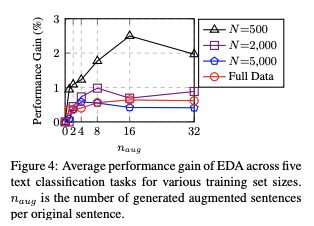
더 큰 훈련셋의 경우, 모델이 일반화가 되는 경우가 있기 떄문에 원래 문장 당 4개 이상의 증강 문장을 추가하는 것은 도움이 되지 않는다고 한다.

코드 구현에서 (alpha_sr=0.1, alpha_ri=0.1, alpha_rs=0.1, p_rd=0.1) 부분인듯
Conclusion
간단한 데이터 증강 연산은 텍스트 분류에 큰 도움이 된다. 100% 성능 향상을 보장할 수는 없지만 소규모 데이터셋에 대한 학습을 진행할 때 성능을 향상시키고 과적합을 감소시킨다고 할 수 있다. (노이즈를 적절하게 만들어줘서 기존 데이터가 부족해 과적합이 나는 현상을 어느정도 방지해준다.)
*KOR_TDA 개발에 관해서는 후에 다시 정리하겠다.
참조사이트
https://catsirup.github.io/ai/2020/04/21/nlp_data_argumentation.html
'프로젝트 > 2021 한이음(probono)' 카테고리의 다른 글
| [프로보노프로젝트/딥러닝] 훈련 / 검증 / 평가 데이터 셋 분할과 홀드아웃 검증(Hold-out validation) (0) | 2021.08.26 |
|---|---|
| [프로보노프로젝트/딥러닝] 패딩 (Padding) (2) | 2021.08.25 |
| [프로보노 프로젝트] 데이터 전처리 개발 중간 백업 (data preprocessing) (0) | 2021.08.10 |
| [프로보노프로젝트/딥러닝] 텍스트 데이터 양 늘리기 (Text Data Augmentation) (4) | 2021.08.09 |
| [프로보노프로젝트/오류해결] AttributeError: 'float' object has no attribute 'lower' (0) | 2021.07.31 |