아마 이번 대회에서 이미지나 영상 데이터 셋을 사용할 것 같은데 텍스트 데이터 셋만 다뤄본 나로서는 선배님들이 데이터 어노테이션을 해야한다는 말을 알아듣지 못했다. 그래서 어노테이션에 대해 공부하고 백업해둔다!
1. 데이터 어노테이션 (data annotation)
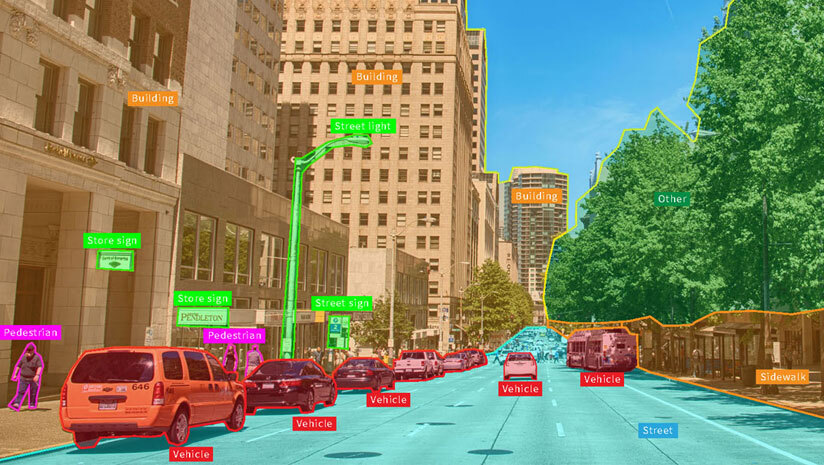
데이터 어노테이션이란 데이터 셋에 메타데이터를 추가하는 작업을 말한다. '태그'형식으로 이미지, 텍스트, 비디오를 비롤한 모든 유형의 데이터에 추가가 가능하다. 쉽게 말해 인공지능이 데이터의 내용을 이해할 수 있도록 주석을 달아주는 작업이라고 할 수 있다.
*메타데이터 : 데이터에 대한 데이터, 어떤 목적을 가지고 만들어진 데이터, 다른 데이터를 설명해주는 데이터, 콘텐츠에 부여되는 데이터
정확도는 어노테이션의 모든 것을 의미한다. 어노테이션이 정확하지 않으면 잘못된 해석으로 이어질 수 있으며 특정 상황에서는 정답을 이해하기가 더 어려워질 수 있다. 더 나은 어노테이션이 포함될수록 기계는 인간이 일반적으로 처리하는 시간 소모적인 작업을 더 잘 수행할 수 있다.
우리나라에서는 데이터 가공에 대해 말할 때 데이터 어노테이션 이라는 표현 보다는 데이터 라벨링이라는 표현이 더 많이 쓰인다고 한다. 기본적으로 데이터 라벨링과 데이터 어노테이션은 데이터상 객체에 태그하는 스타일과 유형을 제외하고는 큰 차이가 없다. 두 가지 모두 인공지능 학습용 데이터를 만드는 데 사용된다. (한이음 프로젝트를 할 때 텍스트데이터에 정답데이터를 알려주기 위해 데이터 라벨링 작업을 거쳤는데 그것과 비슷한 맥락인가 보다.)
2. 어노테이션 기법
2.1 바운딩 박스 (Bounding Box)

바운딩 박스는 이미지 혹은 영상 안 객체의 가장자리에 딱 맞춘 사각형 틀을 그려 캡쳐하는 어노테이션 기법이다. 대표적으로 자율주행 차량이 실제 시나리오에서 주변 환경과 모든 물체를 인식하고 이해하도록 훈련하는데 활용된다.
장 : 쉽고 빠른 데이터 가공이 가능
단 : 객체의 유형과 위치에 따라 바운딩 박스 안에 해당 객체에 속하지 않는 픽셀이 포함될 수 있음
2.2 폴리곤(polygon)
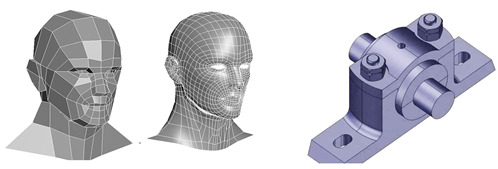
폴리곤은 훨씬 정확하게 객체에 속한 픽셀을 어노테이션 할 수 있는 기법이지만, 작업 속도가 느리다. 일반적으로 객체 테두리의 모든 지점을 표시해 해당 객체를 인식하게 하는데, 길 위에 있는 보행자나 자전거같이 규칙적이지 않은 형태의 객체를 정밀하게 선택할 수 있다. 그래서 바운딩 박스보다는 폴리곤 기법으로 훈련된 데이터가 훨씬 효과적으로 작동한다.
장 : 객체의 윤곽을 정밀하게 선택할 수 있어 인공지능에게 그 물체의 크기과 형태를 정확하게 인식시킬 수 있음
단 : 겹쳐져 있는 객체에 폴리곤 기법을 적용하는 경우에는 목표물을 정확하게 인식하기 어려움
2.3 폴리라인(poly line)

폴리라인은 동일한 장소에서 시작하고 종료할 필요가 없는 형태를 추적할 때 좋다. 객체 테두리에 여러 점을 찍어 선으로 구성되어 나타내는 기법이다. 시작점과 끝점이 달라고 인식이 가능하다. 자율 주행 자동차의 차선 탐지 훈련, 물류창고의 컨베이어 벨트 탐지 훈련 등에 쓰이고 있다.
장 : 전선 감지, 차선 감지 등 직선 혹은 곡선을 추적해야 하는 특정 사례에 유용함
단 : 이미지 상 객체의 선이 1픽셀너비에 가까운 경우에만 작동하기 때문에 객체의 선 너비가 넓은 경우엔 폴리곤 기법으로 대체해아 함
2.4 포인트 (point)
포인트는 이미지 속 객체의 개수를 계산하거나 군중 속에 있는 사람을 선택하는 등, 이미지상 단일 픽셀을 찾아내는 경우에 매우 유용하게 사용된다.
장 : 작업 방법이 매우 쉽고 간단함
단 : 윤곽이 명확하지 않으면 적용하기 힘듦
2.5 큐보이드(Cuboid)

'큐보이드'는 바운딩 박스와 굉장히 비슷한 방식의 기법이다. 하지만 길이와 너비만 나타낼 수 있는 바운딩 박스와는 달리 큐보이드는 길이와 너비 그리고 '폭'까지 나타낼 수 있다. 큐보이드를 사용하면 2D 이미지만으로는 부족한 정밀도를 높일 수 있다. 산업로봇과 같은 기계가 물체를 더욱 정확하게 인식할 수 있게 하는 경우에 흔히 사용된다.
장 : 객체의 깊이에 대한 정보가 제공되기 때문에 3D 환경에서 중요한 정보들을 식별하는 데 도움됨
단 : 객체가 불규칙한 형태를 가지거나 가려진 부분이 있는 경우, 잘린 부분이 있는 경우엔 작업이 어려울 수 있음
2.6 시맨틱 세그멘테이션 (Semantic segmentation)

'시맨틱 세그멘테이션'은 이미지에 있는 모든 픽셀을 채색하고 해당하는 클래스로 분류하는 방식의 기법이다. 주로 자율 주행 자동차, 의료 영상 분석, 산업 검사, 위성 영상, 로봇 비전 등에 유용하게 활용된다. 단순히 사진만 분류하는 작업이 아닌 이미지 속 모든 장면과 상황을 인식할 수 있게 가공하는 고차원의 방법이다.
장 : 이 방식을 이용해 이미지를 가공하면 기계가 해당 장면을 완벽히 이해할 수 있기 때문에 적용분야가 무궁무진함
단 : 이미지의 모든 픽셀을 해당하는 클래스로 분류해야하기 때문에 많은 작업 필요함
참고
-https://m.blog.naver.com/PostView.naver?blogId=datahive&logNo=222224206050&categoryNo=7&proxyReferer=
-https://appen.com/blog/data-annotation/
+)

그리고 이건 갑자기 데이터사이언티스트에 대해 관심이 생겨 찾아보던 중 '데이터 사이언티스트의 현실'이라는 제목으로 발견한 글인데 문득 전공 교수님께서 해주신 말이 떠올랐다. 보안 담당자나 소방관은 직업적으로는 다르지만 무언가를 막는 부분에선 같다고 하셨다. 소방관은 수많은 사람을 구해내고 화재를 진압해내지만, 한 번 막지 못했을 때 돌아오는 질타와 비난이 엄청나다. 보안 담당자 역시 해커의 공격을 막고 있을 때는 그 역할이 눈에 띄지 않다가 단 한번의 허점에 공격이 먹혀버리면 '그것도 못막아?' 가 되어버린다.
IT업계의 양면성인거 같다. 상대적으로 결과물을 창출해내는 개발직군은 눈에 보이는 성과가 있으니 점점 더 대우받고 백그라운드에서 작업하는 데이터사이언티스트나 보안 담당자(관제 등)는 상대적으로 대우가 아쉬운게 사실이다. 그러다보니 위의 글 처럼 성능 향상에 초점을 두고 발전시키기보단 기존 툴을 가지고 대량생산하는 것과같은 의미없는 악순환이 반복되는 것 같다.
돈을 주고 일을 시키는 회사 입장에서도 안보이는 곳에서 노력하는 보안담당자보다는 눈에 보이는 성과를 가져가는 개발자에게 연봉을 인상해주는게 당연하다고도 생각된다. 이런 부분이 개선되어야 할텐데 의사 결정권을 가지고 연구를 하는 연구원이 아니라면 현실적으로 힘들겠지 교수님과 상담했을 때 끌려다니는 삶 말고 주도적인 삶을 살았으면 좋겠다고 말씀하신 부분이 이해가 된다. 단지 글 하나만 읽었을 뿐인데 왜이렇게 생각이 많아지는 지 모르겠다...
'프로젝트 > 2022 융합보안논문경진대회' 카테고리의 다른 글
| [딥러닝] 활성함수 소프트맥스 (softmax) (0) | 2021.12.27 |
|---|---|
| [딥러닝 / 논문 리뷰 ] Attention is all you need (NIPS 2017) (0) | 2021.12.27 |
| [딥러닝 / RNN ] attention mechanism (0) | 2021.12.27 |
| [딥러닝 / RNN] Sequence To Sequence (Seq2Seq Model) (0) | 2021.12.27 |