attention mechanism 등장 배경
Seq2Seq 모델은 인코더에서 입력 시퀀스를 context vector라는 하나의 고정된 크기의 벡터 표현으로 압축한다. 하지만 이런 Seq2Seq모델은 이전 게시글에서 정리했듯 두 가지 문제가 존재한다.
1. 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 내용이 많아지면 정보 손실이 발생한다.
2. RNN(LSTM)의 고질적인 문제인 경사도 손실 문제가 존재한다.
결론적으로, 입력 문장이 긴 상황에서 기계 번역의 성능이 낮아지는 현상이 나타났고, 이런 현상을 보완하기 위하여 중요한 단어에 집중하여 Decoder에 바로 전달하는 attention 메커니즘이 등장하게 되었다.
attention mechanism 작동 방식

이 예제를 통해서 구체적으로 설명하자면 i love you 를 받아서 나온 결과물 h3는 전통적인 Seq2Seq 모델에선 이게 문맥벡터였다. 하지만 attention 모델에서는 조금 다르게 FC를 사용하여 h1,h2,h3 인코더 파트에서 나왔던 모든 RNN 셀의 스테이트들을 활용하는 것이다. 그리고 최종적으로 나왔던 h3를 다시 넣는다. 왜냐하면 지금 상태론 디코더에서 나온 값이 하나도 없기 때문이다. 그렇게 해서 나온 값들이 각 score 1 score 2 score 3 이다. 여기에 softmax 활성 함수를 취해주면 확률값이 출력된다. 현재 출력된 0.9 0.0 0.1 을 각 attention weight라고 부르고 이 값에 따라 중요도가 결정된다.
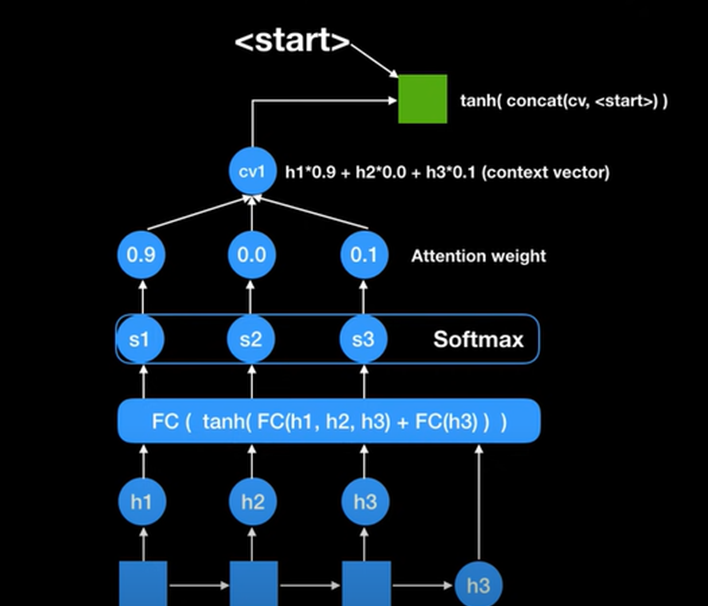
이 식에 따라 계산한 값인 context vector 1은 이 값은 앞의 에제 I Love You 중 I에 90% focus 한 값이 된다 이 값을 decoder 파트에 있는 RNN 셀에 넣어주는 과정에서 이 값은 decoder 의 처음 값이기 때문에 <start>라는 신호를 먼저 넣어주어야 한다. 그럼 "난" 이라는 처음 아웃풋이 나오게 된다. 이 것이 하나의 과정이 된다.
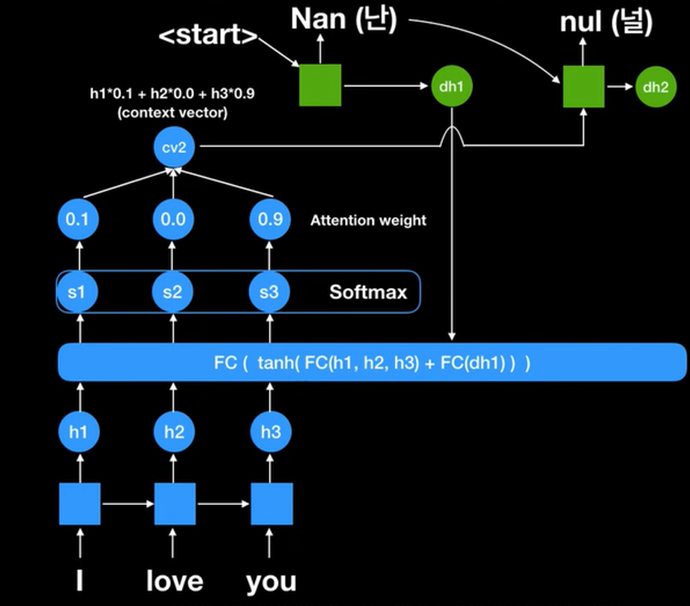

두번째 과정에선 현재 decoder의 값에 FC 값이 들어가있으므로 이 값을 바탕으로 다시 계산해보면 I 10% 유 90%에 focus 된 값이 출력된다. 따라서, 첫번째 과정과 다른 context vector 값이 나왔음을 알 수 있다. 과거에 하나의 context vector만 사용한 모델보다 더 다양하고 방대한 정보를 처리할 수 있다는 장점이 있다.
Seq2Seq vs Attention

RNN 서치가 어텐션 모델, RNN 인코딩이 전통적인 시퀀스 투 시퀀스 모델입니다 뒤에 붙은 숫자 30과 50은 각각 최대로 넣은 단어의 수를 뜻합니다 그래프를 보시면 어텐션 모델이 훨신 효율적인 결과를 출력하는 것을 볼 수 있습니다
reference
Neural machine translation by jointly learning to align and translate (2014 NIPS)
https://www.youtube.com/watch?v=WsQLdu2JMgI
'프로젝트 > 2022 융합보안논문경진대회' 카테고리의 다른 글
| [딥러닝] 활성함수 소프트맥스 (softmax) (0) | 2021.12.27 |
|---|---|
| [딥러닝 / 논문 리뷰 ] Attention is all you need (NIPS 2017) (0) | 2021.12.27 |
| [딥러닝 / RNN] Sequence To Sequence (Seq2Seq Model) (0) | 2021.12.27 |
| [딥러닝] 데이터 어노테이션이란 (data annotation), 어노테이션 기법 (1) | 2021.09.26 |