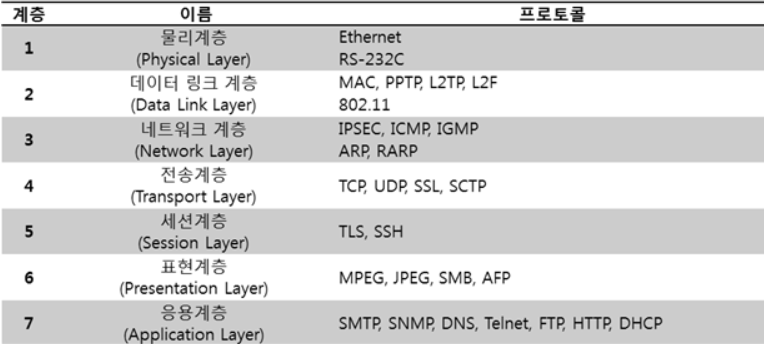
데이터 전처리 개발을 어느정도 완료하고 다음 단계인 머신러닝 trian_data 학습과정으로 넘어가려 하니, 보이스피싱과 관련된 데이터 셋 개수가 너무 적었다. 우리가 사용할 수 있는 금융감독원에 공개된 보이스피싱 텍스트 데이터 셋은 168개 정도인데, 멘토님께 여쭤보니 머신러닝을 학습시킬 때 1만개 이하의 데이터는 의미가 없다고 하셨다. 따라서 현재까지는 머신러닝(딥러닝RNN) 엔진 개발 (1) 데이터 전처리 개발 (2)로 나누었던 팀원의 역할을 재분배하였는데, 그 중 나는 보이스피싱 데이터 셋의 양을 늘리는 프로그램 개발을 맡게 되었다. *또한, 기존 모델 RNN에서 우리의 프로젝트 진행 상황에 따라 로지스틱 회귀 모델로 변경하기로 하였다. 모든게 처음이라.. 잘 할 수 있을지 모르겠지만 우선 구글링..